自分のツイートの頻出単語を1枚の画像にまとめるアプリが、一時期 Twitter で流行ってました。

こんな感じの画像が生成され、頻出度の高い単語ほど大きな文字で表示されています。技術的には MeCab や Janome などによる形態素解析(品詞分解)と WordCloud による可視化が用いられています。その人がどんなことに興味を持っているかがよくわかり、じっくり見てみるとなかなか面白いです。
しかし Twitter の連携アプリでは過去ツイートを遡れる件数に上限があるため、10年以上毎日ツイートしつづけている僕にとっては不十分でした。やはり分析するなら過去全件を調べてみたいですもんね。そこで自分でツイート履歴をダウンロードして分析してみることにしました。
プログラム
作成したプログラムは Github で公開しています(今回はじめて Github を使いました)
参考サイトはソースコード末尾に列挙しました。特にからあげさんのブログ記事で公開されているプログラムが、やりたいこととマッチしていて参考になったので、ここにも載せておきます。
テキストマイニングの方法
Github で公開しているプログラム にアクセスして「Open In Colab」というボタンをクリックすると、難しい環境構築は不要で Google Colaboratory を用いて誰でも簡単に実行できます。
先頭のブロックから順にプログラムを実行していくと、上記のブロックで「ファイル選択」というボタンが出てきます。ここから tweet.js をアップロードしてください。そこそこ時間が掛かります。僕の場合は30分ほど掛かりました。
tweet.js は、事前に Twitter の設定画面の「データのアーカイブをダウンロード」から入手しておく必要があります。
ダウンロードしたファイルの data フォルダの中に tweet.js が入っています。ツイート数が多い場合は tweet.js, tweet-part1.js, tweet-part2.js, ... と分割されていることもあります。
ツイート分析結果
それでは僕の過去10年間・約12万件に及ぶツイートの分析結果を年度別に見ていきましょう。
2010年度(大学3回生)

大学生らしい単語が目立ちますね。専門科目が増えてきて数学や物理のレポート課題に追われてました。趣味で宇宙や漢字の勉強もしていたようです。
2011年度(大学4回生)

研究室に配属されたので「研究」「卒論」といった単語が上位になりました。通常授業がほとんどなくなって趣味の散策が捗り、左下に「滋賀」「京都」「自転車」といった単語が現れてます。「歴史」に傾倒しすぎて、友人からは「卒論の進捗は大丈夫なのか?」と本気で心配されました。
2012年度(修士1回生)

燦然と輝く「ツイート」の文字。この頃、趣味が Twitter といっても過言ではないぐらいに一日中ツイートしてました。
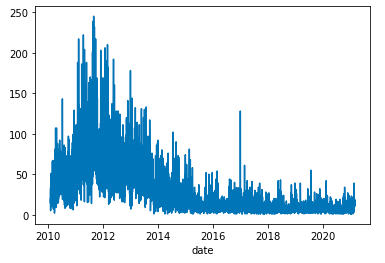
▲日々のツイート数。2012年は1日200件ぐらいツイートしていた。
じっくり調べ事ができる時間が取れたので、漢検1級の問題集を購入して「漢字」の勉強をしたり、日常の有象無象を調べて「雑学」ツイートをしたりしてました。研究は捗ってません。
左上にある「ドラ」が極めて異色ですが、これは勿論「ドラえもん」です。この頃ふと思い立って藤子不二雄同好会に入部したため、ドラえもんツイートが多めになりました。
2013年度(修士2回生)

「京都」「滋賀」を散策してるか、「漢字」の勉強をしてるか、「研究」をしてるかといった感じの日々ですね。就活が終わって競技かるたサークルに久々に顔を出したりもしましたが、「かるた」よりも自室に湧いた害虫「カツオブシムシ」のほうが遥かに文字がでかいです。
2014年度(入社1年目)

社会人になり平日のツイートがぐんと減り、休日に行う趣味の散策ツイートや歴史ツイートが相対的に目立つようになってきました。平日のツイートに関連するのは左下の「Wikipedia」ぐらいですかね。片道1時間半の通勤電車の中で Wikipedia をひたすら読みまくってました。
2015年度(入社2年目)

入社1年目と変わらず全体的に地名が大きいです。古地図や航空写真片手に散策するのに没頭し、「暗渠」「小字」「マンホール」「古墳」といったニッチな領域にどんどん足を踏み入れていってるのがわかります。
右上にある「家系」はラーメンではなく家系図で、戸籍や文献を紐解いて自分のルーツを探るのにも熱中していました。
2016年度(入社3年目)

琵琶湖の水止めたろかツイートがバズった影響で「琵琶湖」がかなり大きくなりました。もう完全に滋賀の人として Twitter で認知されてます。
瀬田川洗堰を全閉して「琵琶湖の水止めたろか!」をシミュレーションしてみた結果、沿岸部と水田地帯がことごとく水没して、甚だしい経済損失が発生した… pic.twitter.com/YJ3lTswzsz
— 風霊守 (@fffw2) 2016年10月17日
入社3年目になると業務負荷が上がってきて「仕事」ツイートも増えてきました。「残業」という単語も目につきます。なるべくネガティブワードは小さくしていきたいものですね。
2017年度(入社4年目)

全体の傾向はだいぶ固定されてきましたね。
特筆すべきは「マンホール」が急に大きくなっていることぐらいでしょうか。
2018年度(入社5年目)

自分の中で「小字」ブーム到来です。小字って何?という人はこちらの解説記事を読んで、沼に足を踏み入れていただければ幸いです。
結婚した影響で「結婚式」「実家」といった単語も現れました。
2019年度(入社6年目)

結婚式が終わって落ち着いたので、本腰を入れて漢検1級の勉強を再開しました。右上を占める「漢字」の文字サイズからその熱量が感じられます。第一子が生まれて「漢字」の横に「出生」といった単語も現れてます。
2020年度(入社7年目)

最近の自分なので心当たりのある単語ばかりです。「滋賀」「草津」「京都」「小字」「地名」などに代表される地理系ツイートが多く、次点が「漢字」といった具合ですね。この傾向は7年ぐらい前から一貫しています。
あとで読むリストを一斉消化した影響で「Wikipedia」がかなり大きく表示されていたり、毎日のように QuizKnock の動画を見てるので「クイズ」「YouTube」といった単語が現れたりしてるのも、2020年度の特徴だと感じました。
プロフィールに活用する
からあげ先生の書籍で WordCloud の分析結果はプロフィールの作成に役立つという話が紹介されていました。目から鱗です。

僕も昔は Twitter のプロフィールに趣味を片っ端から列挙していたのですが、ツイートがバズったときに「あれ?この人○○さんでは?会社の自己紹介ページに書いてる内容と完全に一致してるぞ!」とアカバレ事件(笑)が起きてしまったので、それ以来プロフィールがかなりシンプルになっています。
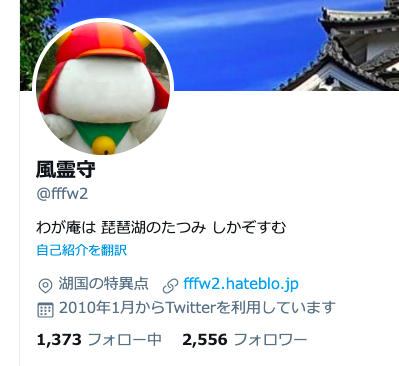
琵琶湖の巽(南東)に住んでることしかわかりません。
流石にあまりにも不親切なプロフィールなので、今回の WordCloud での分析結果を踏まえて、主要なキーワードを付け足してみました!
これで初対面の人も安心ですね。
まとめ
Python でツイート10年分をテキストマイニングして、頻出度を WordCloud で可視化してみました。単語から自分の興味の移り変わりを調べることで、ちょっとした人生の振り返りになりました。
プログラムを Github で公開しているので、興味のある人は是非使ってみてください。